|
link 23.01.2014 17:29 |
|
Subject: ОФФ: Memo Q и работа с текстом в таблице gen. Тут у меня такая проблема, хотелось бы узнать, как с ней другие пользователи Memo Q справляются (AsIs особенно к Вам взываю о помощи))).У меня в документе таблицы с текстом в них. Пока переводишь сплошной текст - все отлично, но как только таблица, получается, что вместо того, чтобы в сегментах отображался текст, идущий вниз по колонке, в нем отображается текст, идущий по строчке, т.е. сегменты один за другим идут, но каждый представляет собой строчку из каждой колонки. Как-то можно это справить? Может в настройках есть? |
| А зачем нужны сегменты, идущие вниз по столбцу? Вы таблицы именно так читаете (сверху вниз по каждому столбцу)? Меня лично вполне устраивает сегментация по строкам и обычное чтение таблиц слева направо по строкам |
|
Пока AsIs не пришел, ценный вклад в варварское обращение с файлом: 1. Выделить и скопировать в буфер каждый столбец по отдельности |
|
И кто-то там говорил, что эта гм.. программа удобней традоса? фууу... |
|
Enote 23.01.2014 20:57 link А зачем нужны сегменты, идущие вниз по столбцу? Иногда такое бывает нужно. Например, в инвойсах и/или каких-то перечнях, например, запчастей, каких-то регламентах. Когда идет несколько столбцов, один столбец нужно перевести полностью, еще один - частично, а еще один - не трогать. У меня такое случается довольно часто. Как я выхожу из ситуации я написал выше. Не исключаю, что есть и более эффективные способы. Dimking 24.01.2014 0:27 link Это типа потрындеть? А так... Хороший, правильный переводчик чаще всего умело управляется как минимум с двумя "кошками". |
|
2 Val61 В MemoQ есть операция копирования источника и даже (по секрету) групповая. Полагаю, она работает быстрее, чем создание отдельных файлов для каждого столбца таблицы и последующей возни c оригиналом и переводом (а как вы выворачиваетесь при переводе idml, ppt, html, sdlxliff, например ?) 2 Dimking Подтверждаю - для меня MemoQ намного удобнее Традоса. Хотя на вкус, на цвет товарищей нет. |
|
link 24.01.2014 6:16 |
|
Val61, у меня вот такая ситуация: если инфа в таблице выглядит в такой последовательности: В лесу В лесу Зимой и летом То сегменты выстроены таким образом: В лесу Согласитесь, не очень удобно так переводить, нет, я конечно руководствуюсь полем, в котором показано, как будет выглядеть док после перевода, там все нормально, но в процессе перевода неудобно перескакивать с сегмента на сегмент. Val61, спасибо за совет, я еще не пробовала так. |
|
link 24.01.2014 7:36 |
| Зачем морочиться со всеми этими заморочными Традосами и МемоКью, когда есть очень простой МетаТексис? |
|
2 akilam1502 RTFM и ЕЩЁ раз - RTFM Если и это не помогает, то можно прямо в MemoQ открыть пункт меню Edit и посмотреть клавиши для вызова команды копирования источника в перевод (они их зачем-то там указали, прямо в команде) 2 Leonid Dzhepko Насчет замороченности МемоКью поподробнее, если можно. Проще этой программы САТ я встречал только Вордфаст классик, но он слабоват по нынешним временам... |
|
link 24.01.2014 8:04 |
|
Enote, спасибо)))) Мне мне Мемо пока нравится, и перешла я на него из-за того, что в Традосе, при наличии в тексте верхних или нижних индексов, текст после перевода не конвертируется в ворд. Индексы убирала, вставляла, тупо копировала сорс в таргет - в пустую. Мне тут посоветовали переустановить прогу. Айтишники сделали, ничего не изменилось. |
|
Enote: Здесь простое копирование исходника в перевод может помочь, а может и нет. Но в принципе, да. Скопировать, отфильтровать, как-то так. akilam1502: В итоге, глобально, наверное, нужно изменить некоторым сегментам статус, затем отфильтровать по статусу и так переводить, в фильтре. В Мемо Кью есть два довольно мощных инструмента фильтрации: Edit-> Goto Next Settings и собственно фильтры (кнопка в виде воронки). Поигравшись с ними, можно настроить требуемую фильтрацию сегментов и/или чтобы после "В лесу" программа автоматически перепрыгивала на следующий сегмент "Родилась". Конкретнее не скажу, т.к. не вижу вашей таблицы и, к сожалению, сейчас сильно занят. Пробуйте сами. Установите себе на компьютер (если до сих пор нет) TeamViewer, скиньте мне в личку пароль, часов в 19-20 МСК сегодня могу на вашу табличку посмотреть повнимательнее и м.б. подобрать подходящий алгоритм фильтрации. Leonid Dzhepko 24.01.2014 10:36 link В том-то и дело, что он слишком простой, оттого не работает с некоторыми типами и форматами файлов. Или требует лишних телодвижений там, где более сложные CAT выполняют операции автоматически. Время, все упирается во время. "Кошка" должна экономить время, а не создавать проблемы. У Метатексиса действительно сильно урезан по сравнению с Традосом/Мео/Дежей функционал. Я пробовал. Лично мне не подходит. Но это не означает, что не подойдет кому-то еще. Скажем, если у вас 100% работы - в Ворде, то почему и нет. ЗЫ: У меня вот прямо сейчас в работе похожая таблица. Огромная, 25 тысяч слов. Но я пошел как Иван Сусанин, сразу в болото, не стал шоссе искать: скопировал таблицу из Экселя в Ворд и в Ворде посливал ячейки так, чтобы в кажой ячейке был не кусок смыслового юнита, а весь такой юнит целиком. Убил часа два на это. Зато переводить теперь проблем нет. Но я понимаю, что не со всеми таблицами такое можно делать. Просто как вариант. |
|
Val61 я вот к чему: 1. закрыть мемоКу. 2. открыть файл в традосе и сделать проблемные столбцы. 3. закрыть традос, облегченно вздохнуть и дальше наслаждаться мемоКу. простые движенья.. |
|
Dimking, а что Традос как-то иначе сегментирует? Хотя если честно, тоже не улавливаю, в чем проблема традиционного (некитайского) считывания... akilam1502, все кнопки можно задать. Мне первое время привычнее было вставлять по-традосовски, поэтому я сделал тоже Ctrl+Insert. Это все в Tools-Options-Keyboard shortcuts. То, о чем Val61 пишет, выглядит так: 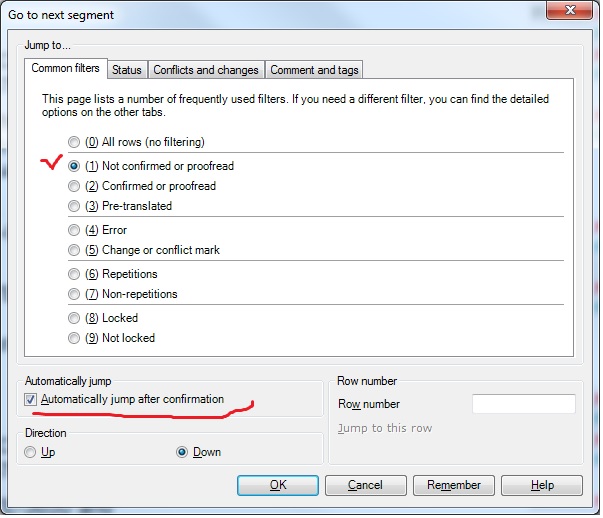 Поставьте такие же галочки, чтобы при подтверждении сегмента перескакивать на неподтвержденный. |
| Еще полезная функция Ctrl+Q. Это быстрое добавление термина в ТВ. В отличие от Студии оно действительно быстрое. Выделяете слово в source, выделяете слово в target, жмете Ctrl+Q - все, слово в ТВ. |
|
AsIs ну тут бы скриншот таблички увидеть, конечно. Если строки таблицы внутри абзаца, как я понимаю, то я бы их объединил. |
|
"строки таблицы внутри абзаца" - не могу представить такое... не знаю, не берусь утверждать... но до сего поста я и внимания не обращал, как оно там что сегментирует. видимо, не было такой надобности. |
Да вот скриншот: 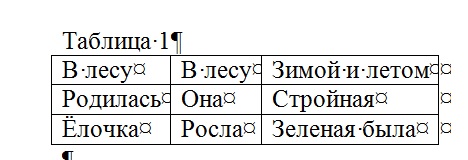 Просто если, допустим, в левой колонке идут термины, а в правой - их определения, то постолбцовое "чтение" не представляется очень удобным. Обычно в ячейках логически завершенный текст идет, а то, что в примере у akilam1502 - весьма редкий случай. Можно и потерпеть. К тому же preview у мемы удобнее реализован - не нужно ждать, пока выплывет, пока нарисует... |
|
AsIs Если "В лесу родилась елочка" принять за абзац, то в нем три строки. В этом случае я бы их объединил |
|
link 24.01.2014 16:51 |
|
ОООоооо, надежда есть! Спасибо огромное за советы! Я таблицу перевела тупо в ворде, ну она на одну страничку была. Вздохнула облегченно. В предвкушении открыла мемо, начала переводить, потом пролистала немного вниз и...О УЖАС, остальные 40 страниц текста в таблице: смысловая информация переходит не от строчки к строчке в каждом столбце, как в случае с дефинициями, а вниз по столбику, как в случае статьи в газете в виде четырех колонок. В общем, счс либо копирую-вставляю, либо последую советам Val 61 и AsIs. |
|
akilam1502, раз уж я взялся поспособствовать вашей миграции с непутевой кошки на путевую, еще пара ключевых настроек: 1. По умолчанию программа в процессе предварительного перевода в пустые ячейки (для которых ничего не найдено) втыкает свой машинный перевод, топорно собираемый из ТМ. Чтобы этого не было, снимите галочки, чтобы было так: 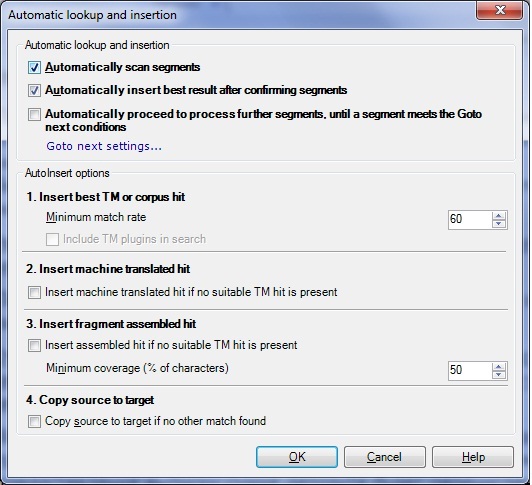 2. В самом окне предварительного перевода по умолчанию стоят галки "Собирать по кускам". На мой взгляд, функция не самая полезная, так как она некотролируемо разбивает и бьет сегменты. Поэтому галочку снимаем, остальное выставляем как на картинке. На второй вкладке делаем так, чтобы 100% совпадения после предварительного перевода были сразу подтвержденными: 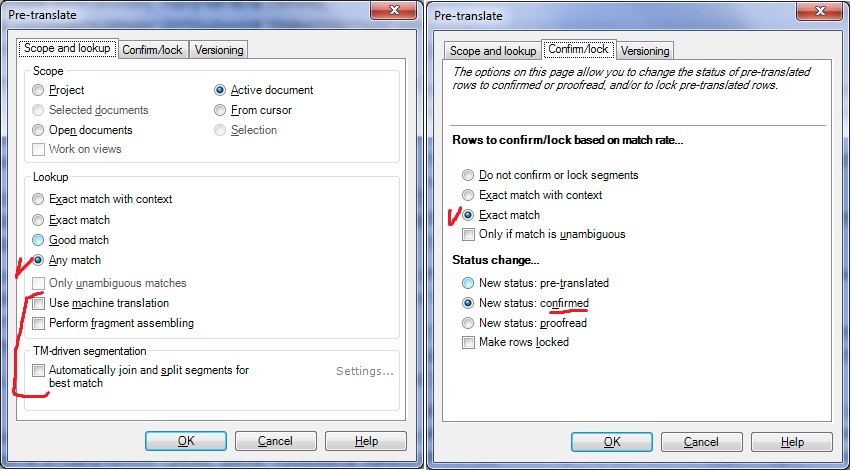 3. Отключить все равно не работающие плагины, чтобы программа не отвлекалась на попытки обращения к ним: 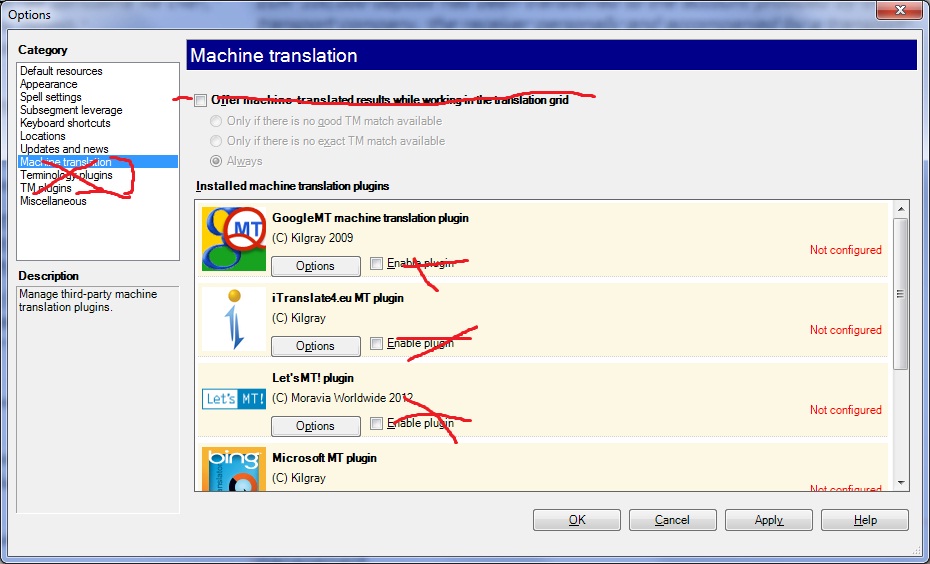 Всё, это основное. Больше мануал перепечатывать не буду. Остальное сами под себя уже наладите (сколько буков автосаджесту задать и прочие мелочи). Удачи! |
| Если текст идет колонками, это уже надо переформатировать, кошка не при чем. Файнридером превращаете в ворд и потом убиваете там все разрывы разделов и разрывы колонок. Но это уже другая песТня... |
|
*разбивает и |
|
link 24.01.2014 17:05 |
|
Установила фильтр, вроде "прыгает", не совсем на те строчки, но намного лучше, чем было. Так что, ребята, вы опять меня избавили от необходимости употреблять больше нецензурных слов, чем обычно. А хотяяя, может, я что-то не так делаю. Тут такой у меня вопрос, аж стыдно спрашивать, но я уже достаточно тут припозорилась своей компьютерной безграмотностью, так что спрошу))): Val61, а как Вам в личку писать? (в Ввашей анкете почта не указана). |
|
link 24.01.2014 17:17 |
| AsIs, Вы "прокачали" мою мемку))) Я все сделала, как Вы показали. Спасибо, порядок наведен. Я мануалы уже начала читать, зря я раньше пренебрегала некоторыми разделами - там очень полезная информация. |
|
как Вам в личку писать? Зайти в форум. Кликнуть по "Добавить тему". Вылезет окошко, под предварительным просмотром есть строка Личное сообщение для _____ (введите имя, сообщение будет показано только данному пользователю) Я его увижу. Если не ответил до того, как оно сползло на другую старницу, апните. |
|
господибожемой.... зачем такие телодвижения?? есть нормальная функция - Import with options.
открываем с ней таблицу. выбираем "Change filter or configuration"
В выпадающем меню Direction of linearization выбираем направление, в котором проге нужно читать инфу из таблицы. Там дается 4е варианта.
Если результат не удовлетворяет, экпериментируем с этими настройками, пока не получим то что нужно. И все)) |



|
Аскер, подсказка - в вашем случае выбирайте вариант чтения 'top-bottom and left-right". т.е. это заставит прогу считывать сперва сверху вниз, потом слева направо. - т.е. колонку А, затем В, затем С... это даст вот такой результат, насколько понимаю, вами желаемый?
|

| А для таблиц в Ворде такой фильтр тоже работает? Или это только для Экселя? |
|
Также, пока не лень отвечать... Сегментация - полезная штука. Но бывает, что в ячейку таблицы запихнуты несколько предложений, которые по идее идут вместе, и оставлять тоже надо вместе. (такое часто встречается в комьютерных играх) А мемка их разбивает на кусочки и отдельные предложения. Идем в настойки сегментации - Project home > Settings > Segmentation rules (с иконкой ножниц, вторая слева) жмем на каждую строчку в обоих окошках и удаляем все нафиг. пока не будет выглядить так: сохряняем и ставим галочку против новых настроек. идет обратно в закладку переводов. Повторно импортируем текст. (функция Reimport document - левая колонка, вторая снизу). Радуемся жизни и мощной проге. ;) |


|
Вал, увы, только для Экселя. В мемке есть функции каскадных фильтров, но у меня от них начинает болеть голова и объяснить вряд ли смогу )) с вордовскими таблицами, в ситуации аскера, я бы сделала так: Или выгрузила бы переведенную таблицу обратно в Эксель и вставила бы в вордовский файл. Как таблицу, чтобы неповадно было)) |
| You need to be logged in to post in the forum |